At Netadvia, we are firm believers in getting the most out of less when it comes to network devices. This philosophy is fuelled by the need to manage device performance against hardware costs, particularly as intelligence and processing power is being pushed towards the network edge.
Today, uCPEs* come in many form factors and price ranges. In general, the differences between uCPE offerings are subtle. The key difference, particularly when it comes to cost, is the CPU architecture at the core of the device. Intel processors are commonly used in this space with two key CPU architectures, Intel Xeon, and Intel Atom. To put it simply, the difference between these processors is processing power, but with this power comes a significant price difference.
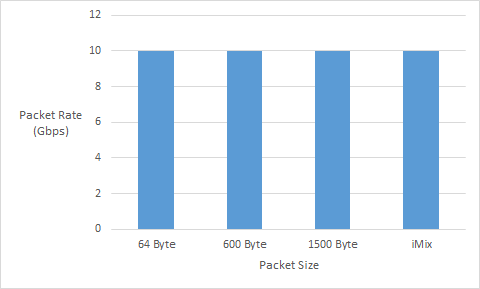
We were interested in testing the performance of lower end, Atom based uCPEs in order to identify if our clients could maximise product performance without incurring the significant cost increase of moving to Xeon. In particular, we wanted to push the limits of what we could achieve on a single Atom core with network traffic driven through a 10G interface.